在线课程地址:https://developers.google.com/machine-learning
10. 逻辑回归
10.1 计算概率
思考一个问题:抛出一个略微弯曲的硬币,硬币正面朝上的概率是多少?
逻辑回归会生成一个介于 0 到 1 之间(不包括 0 和 1)的概率值,而不是确切地预测结果是 0 还是 1。以用于检测垃圾邮件的逻辑回归模型为例。如果此模型推断某一特定电子邮件的值为 0.932,则意味着该电子邮件是垃圾邮件的概率为 93.2%。更准确地说,这意味着在无限训练样本的极限情况下,模型预测其值为 0.932 的这组样本实际上有 93.2% 是垃圾邮件,其余的 6.8% 不是垃圾邮件。
许多问题需要将概率估算值作为输出。逻辑回归是一种极其高效的概率计算机制。实际上,您可以通过下两种方式之一使用返回的概率:
如果逻辑回归模型预测 p(bark | night) 的值为 0.05,那么一年内,狗的主人应该被惊醒约 18 次:
startled = p(bark | night) * nights
18 ~= 0.05 * 365
在很多情况下,您会将逻辑回归输出映射到二元分类问题的解决方案,该二元分类问题的目标是正确预测两个可能的标签(例如,“垃圾邮件”或“非垃圾邮件”)中的一个。
您可能想知道逻辑回归模型如何确保输出值始终落在 0 和 1 之间。巧合的是,S 型函数生成的输出值正好具有这些特性,其定义如下:
S 型函数的曲线图如下:
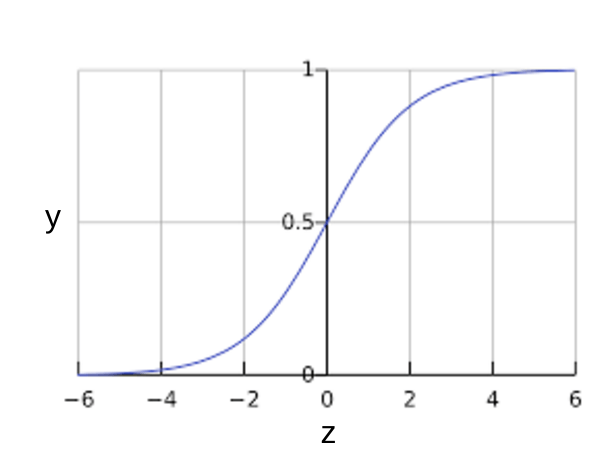
如果 z 表示使用逻辑回归训练的模型的线性层的输出,则 S 型(z) 函数会生成一个介于 0 和 1 之间的值(概率)。
10.2 模型训练
线性回归的损失函数是平方损失。逻辑回归的损失函数是对数损失函数。
正则化在逻辑回归建模中极其重要。如果没有正则化,逻辑回归的渐近性会不断促使损失在高维度空间内达到 0。因此,大多数逻辑回归模型会使用以下两个策略之一来降低模型复杂性:
假设您向每个样本分配一个唯一 ID,且将每个 ID 映射到其自己的特征。如果您未指定正则化函数,模型会变得完全过拟合。这是因为模型会尝试促使所有样本的损失达到 0 ,但始终达不到,从而使每个指示器特征的权重接近正无穷或负无穷。当有大量罕见的特征组合且每个样本中仅一个时,包含特征组合的高维度数据会出现这种情况。
幸运的是,使用 L2 或早停法可以防止出现此类问题。
10.1 计算概率
思考一个问题:抛出一个略微弯曲的硬币,硬币正面朝上的概率是多少?
逻辑回归会生成一个介于 0 到 1 之间(不包括 0 和 1)的概率值,而不是确切地预测结果是 0 还是 1。以用于检测垃圾邮件的逻辑回归模型为例。如果此模型推断某一特定电子邮件的值为 0.932,则意味着该电子邮件是垃圾邮件的概率为 93.2%。更准确地说,这意味着在无限训练样本的极限情况下,模型预测其值为 0.932 的这组样本实际上有 93.2% 是垃圾邮件,其余的 6.8% 不是垃圾邮件。
许多问题需要将概率估算值作为输出。逻辑回归是一种极其高效的概率计算机制。实际上,您可以通过下两种方式之一使用返回的概率:
- “按原样”
- 转换成二元类别。
如果逻辑回归模型预测 p(bark | night) 的值为 0.05,那么一年内,狗的主人应该被惊醒约 18 次:
startled = p(bark | night) * nights
18 ~= 0.05 * 365
在很多情况下,您会将逻辑回归输出映射到二元分类问题的解决方案,该二元分类问题的目标是正确预测两个可能的标签(例如,“垃圾邮件”或“非垃圾邮件”)中的一个。
您可能想知道逻辑回归模型如何确保输出值始终落在 0 和 1 之间。巧合的是,S 型函数生成的输出值正好具有这些特性,其定义如下:
S 型函数的曲线图如下:
如果 z 表示使用逻辑回归训练的模型的线性层的输出,则 S 型(z) 函数会生成一个介于 0 和 1 之间的值(概率)。
10.2 模型训练
线性回归的损失函数是平方损失。逻辑回归的损失函数是对数损失函数。
正则化在逻辑回归建模中极其重要。如果没有正则化,逻辑回归的渐近性会不断促使损失在高维度空间内达到 0。因此,大多数逻辑回归模型会使用以下两个策略之一来降低模型复杂性:
- L2 正则化。
- 早停法,限制训练步数或学习速率。
假设您向每个样本分配一个唯一 ID,且将每个 ID 映射到其自己的特征。如果您未指定正则化函数,模型会变得完全过拟合。这是因为模型会尝试促使所有样本的损失达到 0 ,但始终达不到,从而使每个指示器特征的权重接近正无穷或负无穷。当有大量罕见的特征组合且每个样本中仅一个时,包含特征组合的高维度数据会出现这种情况。
幸运的是,使用 L2 或早停法可以防止出现此类问题。







没有评论:
发表评论