在线课程地址:https://developers.google.com/machine-learning
11. 分类
11.1 阈值
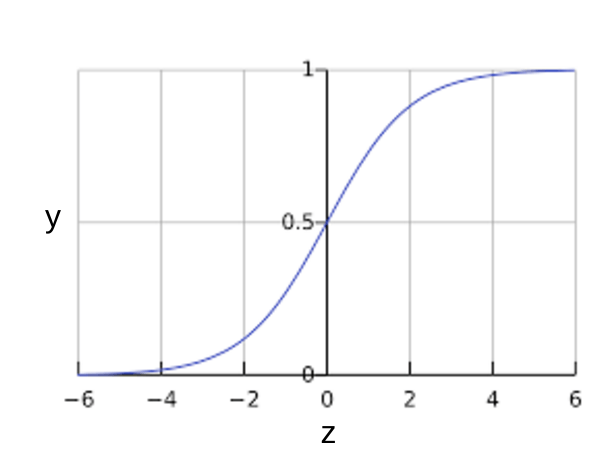
逻辑回归返回的是概率。为了将逻辑回归值映射到二元类别,您必须指定分类阈值(也称为判定阈值)。如果值高于该阈值,则表示“垃圾邮件”;如果值低于该阈值,则表示“非垃圾邮件”。人们往往会认为分类阈值应始终为 0.5,但阈值取决于具体问题,因此您必须对其进行调整。
我们将在后面的部分中详细介绍可用于对分类模型的预测进行评估的指标,以及更改分类阈值对这些预测的影响。
11.2 正分类与负分类
在本部分,我们将定义用于评估分类模型的指标的主要组成部分。
以狼来了故事为例,我们做出以下定义:
我们可以使用一个 2x2 混淆矩阵来总结我们的“狼预测”模型,该矩阵描述了所有可能出现的结果(共四种):






11.1 阈值
逻辑回归返回的是概率。为了将逻辑回归值映射到二元类别,您必须指定分类阈值(也称为判定阈值)。如果值高于该阈值,则表示“垃圾邮件”;如果值低于该阈值,则表示“非垃圾邮件”。人们往往会认为分类阈值应始终为 0.5,但阈值取决于具体问题,因此您必须对其进行调整。
我们将在后面的部分中详细介绍可用于对分类模型的预测进行评估的指标,以及更改分类阈值对这些预测的影响。
11.2 正分类与负分类
在本部分,我们将定义用于评估分类模型的指标的主要组成部分。
以狼来了故事为例,我们做出以下定义:
- “狼来了”是正类别。
- “没有狼”是负类别。
我们可以使用一个 2x2 混淆矩阵来总结我们的“狼预测”模型,该矩阵描述了所有可能出现的结果(共四种):
真正例 (TP):
| 假正例 (FP):
|
假负例 (FN):
| 真负例 (TN):
|
真正例是指模型将正类别样本正确地预测为正类别。
真负例是指模型将负类别样本正确地预测为负类别。
假正例是指模型将负类别样本错误地预测为正类别。
假负例是指模型将正类别样本错误地预测为负类别。
11.3 准确率
让我们来试着计算一下以下模型的准确率,该模型将 100 个肿瘤分为恶性 (正类别)或良性(负类别):
真正例 (TP):
| 假正例 (FP):
|
假负例 (FN):
| 真负例 (TN):
|
准确率为 0.91,即 91%(总共 100 个样本中有 91 个预测正确)。但这是否表示我们的肿瘤分类器在识别恶性肿瘤方面表现得非常出色呢?
实际上,只要我们仔细分析一下正类别和负类别,就可以更好地了解我们模型的效果。在 100 个肿瘤样本中,91 个为良性(90 个 TN 和 1 个 FP),9 个为恶性(1 个 TP 和 8 个 FN)。在 91 个良性肿瘤中,该模型将 90 个正确识别为良性。这很好。不过,在 9 个恶性肿瘤中,该模型仅将 1 个正确识别为恶性。这是多么可怕的结果!9 个恶性肿瘤中有 8 个未被诊断出来!
虽然 91% 的准确率可能乍一看还不错,但如果另一个肿瘤分类器模型总是预测良性,那么这个模型使用我们的样本进行预测也会实现相同的准确率(100 个中有 91 个预测正确)。换言之,我们的模型与那些没有预测能力来区分恶性肿瘤和良性肿瘤的模型差不多。
当您使用分类不平衡的数据集(比如正类别标签和负类别标签的数量之间存在明显差异)时,单单准确率一项并不能反映全面情况。
精确率和召回率这两个指标能够更好地评估分类不平衡问题。
11.4 精确率和召回率
精确率尝试回答的问题是:在被识别为正类别的样本中,确实为正类别的比例是多少?
注意:如果模型的预测结果中没有假正例,则模型的精确率为 1.0。
让我们来计算一下肿瘤分类器的精确率:
该模型的精确率为 0.5,也就是说,该模型在预测恶性肿瘤方面的正确率是 50%。
召回率尝试回答的问题是:在所有正类别样本中,被正确识别为正类别的比例是多少?
注意:如果模型的预测结果中没有假负例,则模型的召回率为 1.0。
让我们来计算一下肿瘤分类器的召回率:
该模型的召回率是 0.11,也就是说,该模型能够正确识别出所有恶性肿瘤的百分比是 11%。
精确率和召回率:一场拔河比赛
要全面评估模型的有效性,必须同时检查精确率和召回率。遗憾的是,精确率和召回率往往是此消彼长的情况。也就是说,提高精确率通常会降低召回率值,反之亦然。请观察下图来了解这一概念,该图显示了电子邮件分类模型做出的 30 项预测。分类阈值右侧的被归类为“垃圾邮件”,左侧的则被归类为“非垃圾邮件”。
从 0 到 1.0 的数轴,其中放置了 30 个样本。
根据上图将电子邮件归类为垃圾邮件或非垃圾邮件。
| 真正例 (TP):8 | 假正例 (FP):2 |
| 假负例 (FN):3 | 真负例 (TN):17 |
精确率指的是被标记为垃圾邮件的电子邮件中正确分类的电子邮件所占的百分比,即上图中阈值线右侧的绿点所占的百分比:0.8
召回率指的是实际垃圾邮件中正确分类的电子邮件所占的百分比,即上图中阈值线右侧的绿点所占的百分比:0.73
一组相同的样本,但分类阈值略有提高。
提高分类阈值,假正例数量会减少,假负例数量会增加。结果,精确率有所提高:0.88,而召回率则有所降低:0.64。
一组相同的样本,但分类阈值有所降低。
降低分类阈值,假正例数量会增加,假负例数量会减少。结果,精确率有所降低:0.75,而召回率则有所提高:0.82。
11.5 检查理解准确率、精确率和召回率
问题1:一只造价昂贵的机器鸡每天要穿过一条交通繁忙的道路一千次。某个机器学习模型评估交通模式,预测这只鸡何时可以安全穿过街道,准确率为 99.99%。
分析1:在一条交通繁忙的道路上,99.99% 的准确率充分表明该机器学习模型的作用比碰运气要好得多。不过,在某些情况下,即使偶尔出现错误,代价也相当高。99.99% 的准确率意味着这只昂贵的鸡平均每 10 天就要更换一次。(这只鸡也可能对它撞到的汽车造成严重损坏。)
问题2:一种致命但可治愈的疾病影响着 0.01% 的人群。某个机器学习模型使用其症状作为特征,预测这种疾病的准确率为 99.99%。
分析2:在这种情形中,准确率是个糟糕的指标。毕竟,即使它只是个一律预测“没病”的“愚蠢”模型,也依然能达到 99.99% 的准确率。而将某个患病的人错误地预测为“没病”则可能是致命的。
问题3:在 roulette 游戏中,一只球会落在旋转轮上,并且最终落入 38 个槽的其中一个内。某个机器学习模型可以使用视觉特征(球的旋转方式、球落下时旋转轮所在的位置、球在旋转轮上方的高度)预测球会落入哪个槽中,准确率为 4%。
分析3:这个机器学习模型做出的预测比碰运气要好得多;随机猜测的正确率为 1/38,即准确率为 2.6%。尽管该模型的准确率“只有”4%,但成功预测获得的好处远远大于预测失败的损失。
11.6 ROC 曲线
ROC 曲线(接收者操作特征曲线)是一种显示分类模型在所有分类阈值下的效果的图表。该曲线绘制了以下两个参数:
- 真正例率 (TPR)
- 假正例率 (FPR)
ROC 曲线用于绘制采用不同分类阈值时的 TPR 与 FPR。降低分类阈值会导致将更多样本归为正类别,从而增加假正例和真正例的个数。下图显示了一个典型的 ROC 曲线。
为了计算 ROC 曲线上的点,我们可以使用不同的分类阈值多次评估逻辑回归模型,但这样做效率非常低。幸运的是,有一种基于排序的高效算法可以为我们提供此类信息,这种算法称为曲线下面积。
曲线下面积:ROC 曲线下面积
曲线下面积表示“ROC 曲线下面积”。也就是说,曲线下面积测量的是从 (0,0) 到 (1,1) 之间整个 ROC 曲线以下的整个二维面积(参考积分学)。
曲线下面积对所有可能的分类阈值的效果进行综合衡量。曲线下面积的一种解读方式是看作模型将某个随机正类别样本排列在某个随机负类别样本之上的概率。以下面的样本为例,逻辑回归预测从左到右以升序排列:
正分类和负分类样本按逻辑回归分数以升序排列。
图 6. 预测按逻辑回归分数以升序排列。
曲线下面积表示随机正类别(绿色)样本位于随机负类别(红色)样本右侧的概率。
曲线下面积的取值范围为 0-1。预测结果 100% 错误的模型的曲线下面积为 0.0;而预测结果 100% 正确的模型的曲线下面积为 1.0。
曲线下面积因以下两个原因而比较实用:
- 曲线下面积的尺度不变。它测量预测的排名情况,而不是测量其绝对值。
- 曲线下面积的分类阈值不变。它测量模型预测的质量,而不考虑所选的分类阈值。
不过,这两个原因都有各自的局限性,这可能会导致曲线下面积在某些用例中不太实用:
- 并非总是希望尺度不变。 例如,有时我们非常需要被良好校准的概率输出,而曲线下面积无法告诉我们这一结果。
- 并非总是希望分类阈值不变。 在假负例与假正例的代价存在较大差异的情况下,尽量减少一种类型的分类错误可能至关重要。例如,在进行垃圾邮件检测时,您可能希望优先考虑尽量减少假正例(即使这会导致假负例大幅增加)。对于此类优化,曲线下面积并非一个实用的指标。
11.7 预测偏差
逻辑回归预测应当无偏差。(为什么?)即“预测平均值”应当约等于“观察平均值”,预测偏差指的是这两个平均值之间的差值。
如果出现非常高的非零预测偏差,则说明模型某处存在错误,因为这表明模型对正类别标签的出现频率预测有误。
例如,假设我们知道,所有电子邮件中平均有 1% 的邮件是垃圾邮件。如果我们对某一封给定电子邮件一无所知,则预测它是垃圾邮件的可能性为 1%。同样,一个出色的垃圾邮件模型应该预测到电子邮件平均有 1% 的可能性是垃圾邮件。(换言之,如果我们计算单个电子邮件是垃圾邮件的预测可能性的平均值,则结果应该是 1%。)然而,如果该模型预测电子邮件是垃圾邮件的平均可能性为 20%,那么我们可以得出结论,该模型出现了预测偏差。
造成预测偏差的可能原因包括:
特征集不完整
数据集混乱
模型实现流水线中有错误?
训练样本有偏差
正则化过强
您可能会通过对学习模型进行后期处理来纠正预测偏差,即通过添加校准层来调整模型的输出,从而减小预测偏差。例如,如果您的模型存在 3% 以上的偏差,则可以添加一个校准层,将平均预测偏差降低 3%。但是,添加校准层并非良策,具体原因如下:
您修复的是症状,而不是原因。
您建立了一个更脆弱的系统,并且必须持续更新。
如果可能的话,请避免添加校准层。使用校准层的项目往往会对其产生依赖 - 使用校准层来修复模型的所有错误。最终,维护校准层可能会令人苦不堪言。
注意:出色模型的偏差通常接近于零。即便如此,预测偏差低并不能证明您的模型比较出色。特别糟糕的模型的预测偏差也有可能为零。例如,只能预测所有样本平均值的模型是糟糕的模型,尽管其预测偏差为零。
分桶偏差和预测偏差
逻辑回归可预测 0 到 1 之间的值。不过,所有带标签样本都正好是 0(例如,0 表示“非垃圾邮件”)或 1(例如,1 表示“垃圾邮件”)。因此,在检查预测偏差时,您无法仅根据一个样本准确地确定预测偏差;您必须在“一大桶”样本中检查预测偏差。也就是说,只有将足够的样本组合在一起以便能够比较预测值(例如 0.392)与观察值(例如 0.394),逻辑回归的预测偏差才有意义。
您可以通过以下方式构建桶:
以线性方式分解目标预测。
构建分位数。
请查看以下某个特定模型的校准曲线。每个点表示包含 1000 个值的分桶。两个轴具有以下含义:
x 轴表示模型针对该桶预测的平均值。
y 轴表示该桶的数据集中的实际平均值。
两个轴均采用对数尺度。
x 轴表示预测值;y 轴表示带标签值。对于中等和较高的预测值,预测偏差可以忽略不计。对于较低的预测值,预测偏差相对较高。
图 8. 预测偏差曲线(对数尺度)
为什么只有模型的某些部分所做的预测如此糟糕?以下是几种可能性:
训练集不能充分表示数据空间的某些子集。
数据集的某些子集比其他子集更混乱。
该模型过于正则化。(不妨减小 lambda 的值。)